lab1: xv6 & unix utilities
配置
环境:ubuntu20.04
跟着xv6-riscv-fall19做的:https://github.com/mit-pdos/xv6-riscv-fall19
Lab: Xv6 and Unix utilities:https://pdos.csail.mit.edu/6.828/2019/labs/util.html
安装依赖:
sudo apt-get update && sudo apt-get upgrade
sudo apt-get install git build-essential gdb-multiarch qemu-system-misc gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu clone代码:
git clone git@github.com:mit-pdos/xv6-riscv-fall19.git
# 然后检查一下分支
git branch -a
# 发现对应所有的几个实验,都有一个分支。
# 要做哪个实验,直接check进入,完成之后,`make grade`评分
# 如果哪个 test point没过,会有对应的xxx.out日志文件打印相关信息方便debug。测试环境:
make qemu
qemu-system-riscv64 --version# 在一个xv6目录下
make qemu-gdb
# 打开新的终端,同样目录下
gdb
# 发现有错 Undefined item: "riscv:rv64".
# 然后发现需要risc-gdb没有弄好,需要riscv的gdb,或者可以用8.3.1以上的gdb。启动
首先在kernel.ld这个链接脚本中设置了起始的地址为0x80000000,这个地址也是qemu中首先跳转执行的地址。对应到源码中是kernel/entry.S,可以看到entry.S代码给每个硬件线程设置好sp寄存器,然后跳转到start。
_entry:
# set up a stack for C.
# stack0 is declared in start.c,
# with a 4096-byte stack per CPU.
# sp = stack0 + (hartid * 4096)
la sp, stack0
li a0, 1024*4
csrr a1, mhartid # mhartid:硬件线程id
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
# jump to start() in start.c
call start- 其中la指令是伪指令(load address),stack0在start.c中定义,为每个cpu准备一个栈,每个栈大小写096
li(load immediate),设置寄存器a0为4096- csrr(Control System Register)控制系统寄存器,读取数据到寄存器a1
上面的步骤设置为start函数设置了相应的sp寄存器。然后进入kernel/start.c的start()函数中。
在start函数中,进行各种设置,设置异常程序计数器指针为main函数,即异常处理程序。在start函数中,设置计时器开始,
Util
实现用户进程sleep
- 先看xv-book的第一章
- 参考其他的例子:
user/echo.c,user/grep.c等怎么从命令行接受参数 - 如果用户使用sleep命令没有给出参数,打印出错误信息
- 命令行参数是string类型,使用
user/ulib.c中的函数atoi转换 - 使用sleep系统调用
- 在
kernel/sysproc.c中查看sleep系统调用的实现,在user/.h中查看用户空间的sleep调用,在user/usys.S中查看从用户程序跳入内核的汇编程序。 - 最后确保sleep函数调用了
exit()来退出程序。 - 在Makefile中的UPROGS中添加自己是先的sleep函数,然后编译,就可以在shell运行sleep。
额外的函数:实现uptime用户程序,打印系统启动uptime的ticks数。
解析:
- 在
kernel/start.c中的start函数中,调用了timerinit(),其中注释提到时钟中断间隔为1000000个interval、大概是1/10秒。暂停用户定义的ticks,即sleep参数和用户输入一致。
实现用户进程pingpong
利用管道实现一个ping-pong程序,父进程写入parent_id[1]一个字节,子进程从parent_id[0]读取这个字节,子进程读完之后,把数据写入child_id[1],然后父进程再从child_id[0]读出来。
- 使用
pipe创建管道 - 使用
fork创建子进程 - 使用
read、write读写数据 - 使用
getpid得到进程号
这个比较简单,还用不到覆盖标准输入输出等;重定向
解析:
pipe系统调用怎么实现的
实现用户进程primes
关于管道、重定向
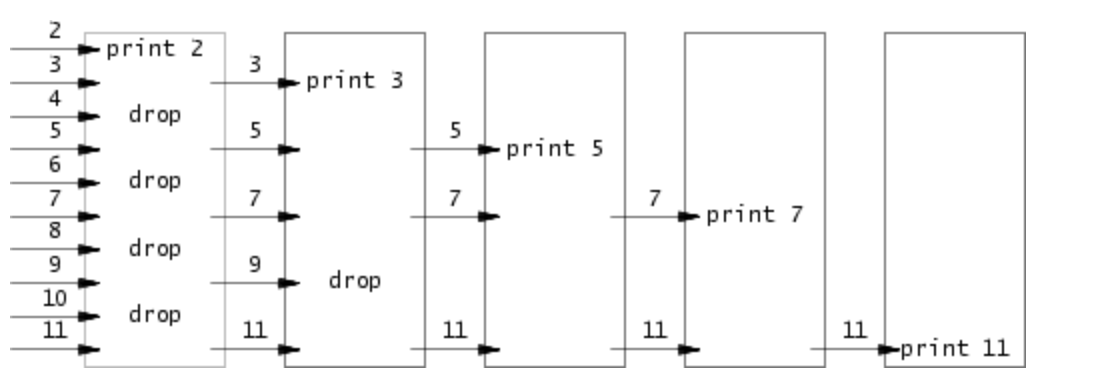
- 写一个并发版本的素数过滤器,
- 使用fork以及pipe建立流水线、第一个进程把数字2-35打入pipe,从左到右输出每一个在其中的素数。
- 参考这个:https://swtch.com/~rsc/thread/,这个图的说明已经非常清楚了。
实现用户进程find
- 先看
user/ls.c,明确怎么读目录 - 递归的遍历子目录
- 不用遍历
.和.. - 对文件系统的更改是持久化的,需要
make clean、然后重新make qemu - 要用到C语言的strings
实现用户进程xargs
- 从标准输入读入多行,然后依次执行
- 对于每行输入,使用fork以及exec系统调用。在父进程中使用wait等待子进程结束
- 每次从标准输入读一个字符,知道读到换行符\n
- 参考kernel/param.h,中的MAXARG
- 对文件系统的更新是持久化的,通过make clean,重新编译make qemu
这儿遇到一个问题,在有argv的情况下,怎么读stdin?
最后发现是我太蠢了,运行程序
./xargs arg1 arg2 ...[\n回车],程序运行了, 然后接下来的输入才对应的是从标准输入中独到的内容。>./xargs grep hello ./a/b ./c/b ./b # 这个命令中"grep hello"是命令行的参数,在输完hello,回车之后程序运行。接下来从./a/b开始的才是标准输入读的内容。 # 如果用一个数组接收标准输入的数据,应该是“./a/b[space]./c/b[space]./b[\n]”最后遇到一个问题,给argv直接追加项,导致没追加签的argv的最后一项的值变了,最后把srgv以及标准输入读的参数复制到另一个数组解决。
文件系统相关概念
在find程序中,参考了ls。find的格式是find <path> <file>,即在路径下找到匹配的文件。那么首先即使要打开path这个文件,所有的路径对应于一个文件。
在文件系统的实现中,文件和目录其实没啥区别,区别仅在于目录文件中放的是目录信息。而文件里面放的是自定义的数据。
因此在实现中,先判断path的类型。
-
如果是文件,判断是否和文件名相同,相同则输出。
-
如果是目录,就从次文件中读一个目录项,直到读完。针对每个读出来的目录项,递归的判断是文件还是目录,然后做相同的处理。
struct dirent { ushort inum; char name[DIRSIZ]; };
在ls程序中,打印出了路径下的所有“文件”,包括文件,目录, 设备(在kernel/stat.h,1表示目录,2表示文件,3表示设备)。“文件”的stat结构体相当于“文件”的元数据,定义在kernel/stat.h
struct stat {
int dev; // File system's disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};其中dev表示的是disk device,表示哪一个磁盘,ino表示在这个磁盘上的inode号码,type表示哪种“文件”,有文件、目录、设备三种;nlink表示链接数量;size表示文件的大小。
通过在xv6中运行ls程序:
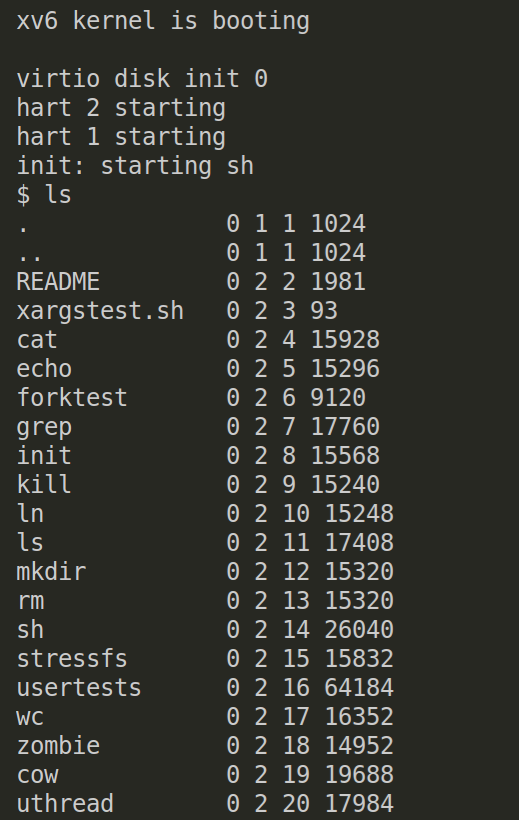
得到的结果表示所有的文件都在同一个磁盘设备,第二列表示文件类型,第三列表示inode号,根据第四列文件大小可以计算inode号。可以看到在这个文件系统中,一个inode负责1kb大小的磁盘空间。
TODO:关于生成文件系统这部分的代码在mkfs,随后在看。
关于怎么把kernel和fs.img链接起来,应该在kernel.ld 链接文件中或者makefile中,这个随后看。
syscall
在xv6的系统调用中,调用顺序是这样的:
user_program --> user_lib(ulib.c) --> user_trap(usys.S) --> syscall -> sys_xxx
# user_lib主要是对系统调用的一个wrap,也可以不调用user_lib,直接调用usys.S中的函数。- 首先在
user目录下的是用户程序,如ls、cat等。 - 上面这些代码可能会使用到系统调用,用户的库的头文件是
user/user.h,声明了系统调用的接口。 - 库文件的实现在
user/usys.S汇编代码真正trap进入内核riscv的系统功能的汇编指令:ecall,携带参数进入内核。其中系统调用号放在寄存器a7
- 由内核中的
kernel/syscall.c中的syscall函数作为系统调用的相应函数,根据不同的中断号执行不同的系统调用sys_xxx函数。
C语言内嵌汇编
参考:https://blog.csdn.net/yt_42370304/article/details/84982864
asm volatile("xxx")- asm:表示后面的是汇编代码
- volatile:表示编译器不需要优化代码,后面的指令保持原样
内嵌汇编语法:__asm__(汇编模板语句:输出部分:输入部分:破坏描述部分)
%0,%1….代表参数,位置互相对应。
static inline uint64
r_mstatus()
{
uint64 x;
asm volatile("csrr %0, mstatus" : "=r" (x) );
return x;
}
// "=r"的意思是:变量放入通用寄存器,并且是只写的
// 对应的汇编:csrr [寄存器], mstatus;寄存器值与x变量绑定,x作为输出参数
static inline void
w_mstatus(uint64 x)
{
asm volatile("csrw mstatus, %0" : : "r" (x));
}
// "r"的意思是:变量放入通用寄存器
// 对应的汇编:csrr mstatus, [寄存器];寄存器值与x变量绑定,x作为输入参数
源码安装gdb8.3.1
PREFIX=$(pwd)/gdb-8.3.1-riscv64-linux-gnu
wget ftp://ftp.gnu.org/gnu/gdb/gdb-8.3.1.tar.xz
tar Jxf gdb-8.3.1.tar.xz
mkdir gdb
cd gdb
../gdb-8.3.1/configure --program-prefix=riscv64-linux-gnu- --enable-tui --target=riscv64-linux-gnu --prefix=${PREFIX}
make all install参考资料
- 3.9 XV6 启动过程
- RISC-V Assembly Programmer’s Manual
- Misunderstanding RISC-V ecalls and syscalls
- CSR(Control and Status Register Instructions):读写寄存器
- AUIPC(Add Upper Immediate to Program Counter):这个指令把PC寄存器的高20位设置为操作数的和,低12位为0
- 在
kernel/syscall.c中syscalls,系统调用数组声明为啥是这样的?https://stackoverflow.com/questions/17807103/array-assignment-by-index-while-declaration-in-c-language;这样声明可以乱序初始化。emm